Library of Babel
25/SEP/2024

Below is the documentation detailing the process of building the library.
You can explore the library here.
The Idea
The initial idea occurred to me after revisiting Jonathan Basile's two-dimensional library of babel and rereading through Jorge Luis Borge's story.
My initial search surrounding the whole topic led me to only one three-dimensional implementation by Keiwan, which also offered a Unity web version for the library.
However, as I tried to explore the implementation of the library, I was greeted with the following exception on my main machine. 
Aside from the technical issue, I also noticed that while the library was rendered in 3D, it seemed to limit movement to only forwards and down, restricting full 3D exploration. The inability to move freely in all directions, which could have unlocked a more immersive experience, felt like a significant limitation in terms of exploring such a vast space.
Whatever the exception was, the desire to shape a solution that did not rely on a Unity web port (however advanced Unity may have become) only encouraged me further to go about implementing a native WebGL version of the entire library and applying my own touch to it.
Thus my journey into the project began...
Outlining the Structure
The initial challenges of the project involved integrating a pseudo-infinite space within a procedurally generated environment while ensuring smooth frame rates for users.
On paper, it seemed easy enough, right? I had previously created pseudo-infinite isometric worlds in two dimensions (similar to how Minecraft operates). With some clever wraparounds and the repetitive nature of the library's design, I thought I could achieve an infinite space using a limited set of pre-defined cells.
However, it quickly became clear that the task was more intricate than I initially anticipated. Establishing the base structures for the library was just the beginning. I would soon face the challenge of developing a coordinate system to track the observer's position relative to rooms, walls, shelves, volumes, and pages — elements that would need to support a pseudo-infinite mapping system. And then there was the encoding and decoding mechanism to link each page's content to unique combinations within the library, as well as the need for robust collision detection for seamless navigation.
So, to recap: just a bit of modeling, range mapping, clever tricks to simulate infinite loops, and collision detection — seems simple enough, right? Yet, as I would discover, the illusion of simplicity was just that. But before diving deeper, I needed to fire up Blender.
The Rooms
I had seen some implementations and artistic images of concepts for the library before, each featuring slight differences.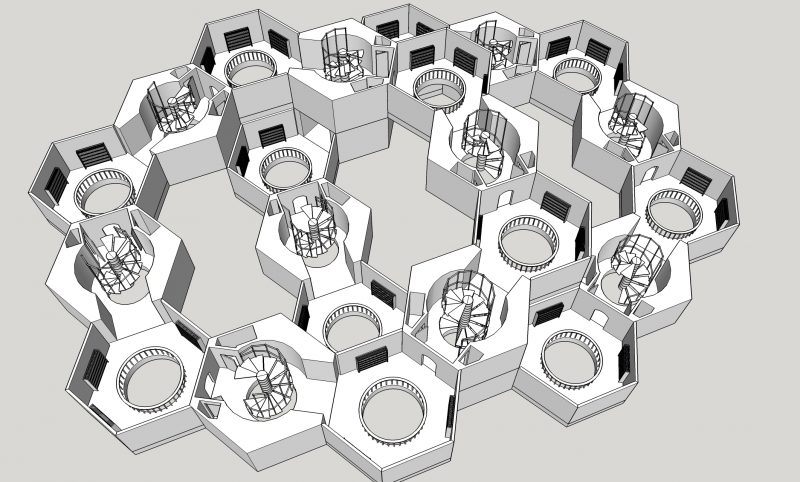


After some modeling, I had the following two models with baked-in lights along with packed 2K textures later on.
A vestibule cell with six exits towards all directions.
Use mouse to 3D inspect
A regular cell with one entrance and one exit and four remaining walls for the books.
Use mouse to 3D inspect

Connecting Rooms
Despite the future techniques I would employ to create the illusion of an infinite world, my immediate concern was to establish a system that would enable me to:
- Construct a grid of interconnected hexagons.
- Assign coordinates to these hexagons.
- Perform arithmetic operations on these coordinates, such as retrieving neighboring cells.
An axial coordinate system, with an origin at zero, would suffice for this task.
“The axial coordinate system, sometimes referred to as 'trapezoidal,' 'oblique,' or 'skewed,' mirrors the cube system except that we do not store the s coordinate. Since we have the constraint q + r + s = 0, we can derive s = -q - r when needed.”- redblobgames
Essentially, I would expand my coordinates in all directions (both positive and negative) from an origin cell located at Q: 0 and R: 0.
- redblobgames

The Anatomy of a Hexagon
However, unlike a standard rectangular pattern where individual shapes can be tiled by precisely offsetting them according to their width and height, hexagons present a unique challenge. In the case of regular hexagons, where all sides are of equal length, the width does not equal the height, despite having a constant radius.

The term "flat-top orientation" refers to a hexagon positioned with its flat side at the top and its pointed vertices oriented to the left and right. The opposite configuration is known as "pointy-top orientation."
As demonstrated above, the width can be calculated by simply doubling the radius. For my model, with a radius of 7, this results in a hexagon width of 14. The height, however, is derived by multiplying the radius by the square root of three, yielding approximately 12.12 for a radius of 7.
The final consideration involves the spacing of the hexagons, ensuring they can seamlessly form a grid. Simply offsetting them by their calculated width and height would not suffice, as this would fail to connect all sides and create gaps within the grid.

“In the flat-top orientation, the horizontal distance between adjacent hexagon centers is horiz = 3/4 * width = 3/2 * size. The vertical distance is vert = height = sqrt(3) * size.”- redblobgames
Armed with this information, I began to implement my HexUtility class in TypeScript, which included the following function to retrieve world positions from given axial coordinates, incorporating the necessary calculations outlined above for spacing.
public static getAxialFromWorld(x: number, z: number, radius: number): { q: number; r: number } {
const q = (Math.sqrt(3) / 3 * x - 1 / 3 * z) / radius;
const r = (2 / 3 * z) / radius;
return this.roundAxialHex(q, r);
}The need to round the result of this calculation (hence the this.roundAxialHex(q, r) call) is crucial; without rounding, the function would return floating-point values for Q and R, merely translating world positions to axial coordinates without snapping them to the grid.
“Similar to integer cube coordinates, frac.q + frac.r + frac.s = 0 with fractional (floating point) cube coordinates. We can round each component to the nearest integer: q = round(frac.q); r = round(frac.r); s = round(frac.s).- redblobgames
However, after rounding, we cannot guarantee that q + r + s = 0. Fortunately, we can correct this issue by resetting the component with the largest change back to what the constraint q + r + s = 0 requires.
For instance, if the r-change abs(r-frac.r) is greater than both abs(q-frac.q) and abs(s-frac.s), we set r = -q - s. This ensures that q + r + s = 0.”
This leads to the following implementation in my class:
public static roundAxialHex(q: number, r: number): { q: number; r: number } {
const s = -q - r;
const rq = Math.round(q);
const rr = Math.round(r);
const rs = Math.round(s);
const qDiff = Math.abs(rq - q);
const rDiff = Math.abs(rr - r);
const sDiff = Math.abs(rs - s);
if (qDiff > rDiff && qDiff > sDiff)
return { q: -rr - rs, r: rr };
else if (rDiff > sDiff)
return { q: rq, r: -rq - rs };
else
return { q: rq, r: rr };
}Thus, I was ready to dive into performing cheap magic tricks to create illusions of infinity...
Infinity

As illustrated by the image, when the observer is about to step onto any of the marked tiles, they are teleported back to the grey root cell.
However, simply teleporting the observer to the center of the root cell won't suffice, as it would break the illusion of continuity.
The illusion of infinity through teleportation.
Use mouse to inspect in 3D
To preserve the illusion, the observer must be teleported to the opposite entrance within the grey origin, ensuring a seamless transition into a new room rather than simply reappearing in the center.
This process is also applied vertically. In this case, the observer is immediately looped back to the top when crossing into the next level, as the lower and upper levels are identical, allowing for a perfect vertical loop.
With that complete, the next step is to implement a first-person camera and a collision system, finally enabling navigation through the library...
Standing on firm ground
The first and simplest optimization was leveraging the fact that the observer moves from cell to cell. By focusing collision checks exclusively on the current cell, we could eliminate unnecessary computations for cells that were outside the observer's immediate vicinity.
The next logical step was to incorporate a more sophisticated technique: a Bounding Volume Hierarchy (BVH) structure to further optimize performance.
“A bounding volume hierarchy (BVH) is a tree structure used to organize geometric objects. Each object is encapsulated within a bounding volume, forming the leaf nodes of the tree.- Wikipedia
These bounding volumes are then grouped into larger bounding volumes, which are themselves grouped recursively, creating a tree structure with a single root bounding volume at the top.
BVH is particularly useful for optimizing operations like collision detection and ray tracing by limiting the number of objects that need to be checked during each query.”
In practical terms, we subdivide the space within each cell by grouping its geometric objects into smaller, manageable clusters. Each cluster is enclosed in a bounding volume. When the observer moves through the environment, we only check for collisions with the relevant bounding volumes rather than all the objects in the cell.

Here's how the process works: instead of checking every object in the cell for collisions, we first check if the observer enters one of the green bounding volumes which represent the volumes of the bounding volume hierarchy.
In an efficient BVH, nodes within any sub-tree should be spatially close to one another, with proximity increasing the deeper they are in the tree.
Each node should enclose its objects in the smallest possible volume, minimizing both the total sum of bounding volumes and the overlap between sibling nodes.
Greater focus should be placed on optimizing nodes closer to the root, as pruning these nodes excludes a larger number of objects from further checks. Additionally, maintaining a balanced tree structure ensures that non-relevant branches can be efficiently pruned during traversal.
Only if a collision with a bounding volume occurs will we perform the more expensive and precise collision detection on the objects contained within that volume. This drastically reduces the number of complex collision checks required.
For instance, the general collider structure for the cell is shown below. The floating shapes in the center represent elevators, which have their own responsive colliders.

Essentially, by organizing objects into a hierarchy of bounding volumes, we minimize the number of expensive collider checks. As the observer moves, we first check for collisions with the larger bounding volumes, which are computationally inexpensive.
Only if a collision is detected within these larger volumes do we proceed with a detailed collision check for the specific objects inside, which is far more resource-intensive.
This two-tier approach ensures smooth performance even in complex environments.
Rendering Optimisations
At the surface level, we are rendering a hexagonal cell pattern consisting of three rings around the origin. Currently, we are rendering the following:

It's clear that we are over-rendering a significant number of cells. The field of view only encompasses a portion of our grid, so we need to avoid rendering anything that lies outside this view.
As an initial step, we will implement frustum culling, an optimization technique that prevents the rendering of objects outside the field of view.
We will establish the frustum coordinates and use the bounding box of each cell to determine if it falls within the frustum.

However, we are still over-rendering certain cells.
If we recall the specific structure of our cells, which feature dedicated entrances and exits, we realize that walls lacking any openings can obstruct visibility to other cells.
For instance, consider the image below, where our field of view originates from the top left and flows through all marked cells.

The doors are marked as small boxes, and not all cells are visible from our position, even if they lie within the frustum.
Some cells are completely obstructed by walls to us due to not having any apparent entrance that we can use to look into them.
The optimization we will implement resembles occlusion culling, which prevents rendering of obstructed objects. To apply this method in our case, we will retrieve all doors from the current cell and traverse in the directions they lead. As we move through the cells accessible via the doors, we will inform our rendering engine to allow rendering of each encountered cell and subsequently retrieve the doors for this new cell, rendering only the next cell it connects to.
A crucial aspect of this approach is that we only deal with a subset of cells that were filtered out during the frustum culling so we can continue filtering. We want to avoid traversing cells that aren't even within the frustum, as that would make occlusion culling more costly than rendering without it.
By combining all these methods, we have successfully reduced our rendering from 37 cells per level to as few as 7 (in the best case) and 16 (in the worst case).
Our final rendering optimization will focus on geometry instancing.
“In real-time computer graphics, geometry instancing is the practice of rendering multiple copies of the same mesh in a scene at once.- Wikipedia
This technique is primarily used for objects such as trees, grass, or buildings, which can be represented as repeated geometry without appearing unduly repetitive, but may also be used for characters.
Although vertex data is duplicated across all instanced meshes, each instance may have other differentiating parameters (such as color or skeletal animation pose) changed to reduce the appearance of repetition.”
Now, consider the following bookshelf.

That's a lot of books — 160 to be precise. With four walls in a cell containing 160 books each, we're looking at 640 individual objects per cell. When rendering multiple cells with these books, the number of objects increases further.
Even if the shape of an individual book is very simple, consisting of only eight vertices and twelve triangles, rendering so many books without optimization will likely prevent us from achieving our target of 60 frames per second on regular machines due to the high number of draw calls. The number of draw calls is often the most significant factor affecting performance.
This is where mesh instancing comes into play. To demonstrate its effectiveness, we can use the analogy of Blender's duplicate linked feature.
Note: Duplicate linked is not the same as instanced meshes; the former reduces memory consumption outside of rendering and may inadvertently enhance rendering performance, while the latter focuses on reducing draw calls by rendering multiple instances in a single call.
With that distinction in mind, consider the following two images:


Notice how, despite the second image containing more books, the geometry data (vertex, edges, faces, triangles) remains unchanged. This occurs because Blender copies over the data of the first book for each subsequent book in the editor.
Once we finalize this last optimization, our rendering process (more specifically WebGL's instanced rendering) will perform a similar operation by sending the geometry data of one book (vertices, normals, etc.) to the GPU in one go. It will then use a small set of additional data (like transformation matrices for position, rotation, and scale) to render multiple copies of that same geometry with different transformations in a single draw call, rather than repeating the entire geometry for each instance.
This approach will allow us to support many individual books while enabling users to highlight them by hovering over them with their mouse, as well as assign different colors to each book, keeping the bookshelf visually interesting.
With all the rendering handled and us looking at overall 60 frames per second, we now dive into the actual library content...
Contemplating 29 letters
This leads to an astronomical total of 293200 unique pages in the library — roughly a 4000-digit number, vastly exceeding the number of atoms in the observable universe (estimated at 1082). The question is: how do we map and retrieve such a vast quantity of pages efficiently?
Thankfully, we don't need to store or memorize every page. Just as we can compute certain values without storing all possible inputs, we can devise a procedure to generate and retrieve a specific page, as long as we know the key input, and in the case of reversing it, know the page's content (or a part of it).
The observer either wanders through the library (where we track movement) or performs a reverse search for a specific word. Thus, we either know the exact location of a page or its content (or part of its content), so we can optimize around those scenarios without storing every possible page.
Early in the development process, I considered using a reversible random number generator to generate pages. However, this approach proved unfeasible given the library's size — larger than the observable universe — and would have required brute-forcing or storing vast amounts of data.
Instead, I adopted an encoding and decoding scheme. With 26 letters plus the comma, period, and space, we have a 29-character set, so our page content can be represented in Base-29. For mapping locations, I chose a base64 encoding scheme to represent page identifiers efficiently.
Now, here's a simple encoding and decoding function:
public static async toContent(key: string) {
let page = Mapper.base64ToPage(key);
let content = "";
while (page > 0) {
const remainder = page % CHARSET_PAGE_BASE;
content = CHARSET_PAGE[Number(remainder)] + content;
page = page / CHARSET_PAGE_BASE;
}
return content || "a";
}
public static async toKey(content: string) {
let index = BIG_ZERO;
for (let i = 0; i < content.length; i++) {
const char = content[i];
const value = BigInt(CHARSET_PAGE.indexOf(char));
index = index * CHARSET_PAGE_BASE + value;
}
return Mapper.pageToBase64(index);
}This enables us to map a base64 identifier (representing the location of our page) to a Base-29 string (representing the page content).
But how do we generate identifiers? To simplify things, let's use integers. The number 0 corresponds to "a", the number 1 to "b", and so on. Once we exceed 29, we move to two-letter combinations like "aa", "ab", and so forth.
Our task is to create a function that can map integers from 0 to 293200 into a string, which we can then encode in base64 for efficiency.
Next, how do we map a 3D location (like a cell's position in space) into a 1D number? One option is the Cantor pairing function.

However, since we're working in 3D, we need to adapt it either by applying it recursively or by using a different method that can handle three dimensions.
A simpler approach is to use a linear combination to flatten the 3D space into a 1D space by constructing a cube. To do this, we need to define the maximum size for each axis. Given the scale of the library, we can confidently say that no dimension (x, y, z) will require more space than the total number of pages in the library times two (to account for negative and positive coordinates). This constraint ensures that the cube's volume will be manageable.
However, not every mapped value on this axis needs as much space as the total number of pages, since a single cell contains multiple pages. So, we can shrink the cube by dividing the total number of pages in the library by the number of pages per cell.
Specifically, dividing 293200 by the product of 640 (books per cell) and 410 (pages per book) gives us a much smaller axis size. This creates a more practical cube size for mapping cells.
To further optimize, we can reduce the space for negative and positive coordinates by calculating the perfect fit for each axis using the cube root function, adjusting for our earlier inflated axis size.
The final function for mapping a cell's Q, R, and level to a single number looks like this. AXIS_LENGTH is the calculated value, and AXIS_TOTAL_SIZE is twice that (for both positive and negative values). All values are offset by AXIS_LENGTH to avoid negative indices.
public static getRoomNumber(q: bigint, r: bigint, level: bigint) {
const qIndex = q + AXIS_LENGTH;
const rIndex = r + AXIS_LENGTH;
level = level + AXIS_LENGTH
return rIndex + qIndex * AXIS_TOTAL_SIZE + (level * AXIS_TOTAL_SIZE * AXIS_TOTAL_SIZE);
}And here's the function to reverse this process and retrieve the original cell coordinates:
public static getRoomLocation(index: bigint) {
const base = AXIS_TOTAL_SIZE;
let level = index / (base * base);
level = level - AXIS_LENGTH;
const remainingIndex = index % (base * base);
const q = (remainingIndex / base) - AXIS_LENGTH;
const r = (remainingIndex % base) - AXIS_LENGTH;
return { q: q, r: r, level: level };
}We can now combine this room number with additional numbers (e.g., the wall, shelf, volume, and page number within the cell) to create a unique identifier for each page’s location.
public static get(room: bigint, wall: bigint, shelf: bigint, volume: bigint, page: bigint): string {
return this.pageToBase64(((((room * WALLS_PER_ROOM + wall) * SHELVES_PER_WALL + shelf) * VOLUMES_PER_SHELF + volume) * PAGES_PER_VOLUME) + page)
}With all these components in place, we are ready to generate and reverse-map pages efficiently...
Combining it all
The user interface is designed to be intuitive and easy to navigate, providing two primary functions:
- Browsing: Users can freely explore the library, turning through pages as they would in a real-world book, discovering randomly generated content across the entire collection.
- Reverse Search: Users can input a word or phrase to locate the exact page in the library where it appears, making the process of finding specific content effortless within the library's structure.
Despite the astronomical number of 293200 possible pages, the interface streamlines navigation, allowing users to focus on exploration and discovery without being overwhelmed by the underlying complexity.
Below are snapshots of the final user interface:

The first interface showcases the browsing mode. It allows the observer to wander through the vast collection of books, flipping through pages one by one. The clean layout makes reading smooth and enjoyable, while navigation controls are placed intuitively for easy exploration.

In the second interface, we see the reverse search functionality. Here, the user can input specific words or phrases and instantly retrieve the page number and location within the library. This powerful search tool makes navigating the infinite library feel straightforward and efficient.

The third interface provides insights into the system's structure, showcasing the mapping between the abstract location and the content itself. This interface offers advanced users a glimpse into how each page is tied to a unique identifier within the vast library.
Now that everything is in place, the library is fully functional, allowing users to explore and locate any of the 293200 unique pages across the entire collection!
You can start exploring the library here. I welcome any feedback or suggestions you may have as I continue to refine and expand this project. Thank you for your input!